Trong quá trình vận hành hệ thống dữ liệu lớn, việc đối mặt với các pipeline xử lý chậm chạm, nghẽn luồng truyền tải hay thời gian hoàn thành backfill kéo dài là điều vô cùng phổ biến. Khi khối lượng thông tin cần nạp tăng lên gấp mười hay gấp trăm lần, những thiết kế pipeline thông thường sẽ nhanh chóng bộc lộ khuyết điểm. Để giải quyết dứt điểm vấn đề này, chúng ta cần một phương pháp tiếp cận toàn diện và bài bản. Đó chính là lý do vì sao kỹ thuật Data Throughput Accelerator Skill ra đời, nhằm mang lại tốc độ vượt trội cho luồng dữ liệu.
Thực tế thì, việc tăng tốc luồng dữ liệu không đơn thuần là câu chuyện cấu hình thêm tài nguyên máy chủ hay nâng cấp băng thông mạng. Nếu bạn thiết kế sai kiến trúc, việc nạp hàng tỷ bản ghi sẽ trở thành cơn ác mộng với vô vàn lỗi trùng lặp hoặc sai lệch thông tin. Với phương pháp Data Throughput Accelerator Skill, mục tiêu tối thượng mà chúng ta hướng đến không chỉ là tốc độ thuần túy, mà là làm thế nào để dữ liệu chính xác cập bến đích với đầy đủ chứng cứ đối soát rõ ràng.
Thú thật là, trước đây tôi đã từng chứng kiến nhiều đội ngũ kỹ thuật cố gắng giải quyết bài toán hiệu năng bằng cách ép hệ thống chạy song song vô tội vạ. Kết quả là cơ sở dữ liệu đích bị quá tải, các bản ghi bị khóa (lock) chéo nhau, và cuối cùng tiến độ tổng thể còn chậm hơn ban đầu. Khi áp dụng Data Throughput Accelerator Skill, chúng ta sẽ đi qua một bộ quy tắc và heuristics đã được kiểm chứng thực tế, giúp tối ưu hóa từng điểm nghẽn mà không làm tổn hại đến tính toàn vẹn của dữ liệu.
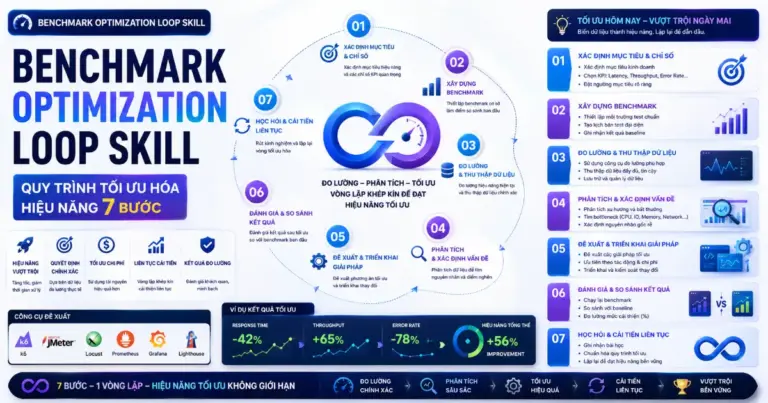
Phân Biệt 6 Điểm Nghẽn Trong Data Throughput Accelerator Skill
Trước khi bắt tay vào cấu hình bất kỳ tham số tối ưu nào của Data Throughput Accelerator Skill, công việc đầu tiên và quan trọng nhất của một kỹ sư dữ liệu là bóc tách và phân biệt rõ ràng các phân đoạn trong hệ thống. Một đường ống dữ liệu dài luôn chứa đựng nhiều trạm trung chuyển khác nhau. Việc nhầm lẫn giữa tốc độ đọc nguồn và tốc độ lưu kho sẽ khiến bạn lãng phí thời gian tối ưu sai chỗ khi thiết lập Data Throughput Accelerator Skill.
Khi tối ưu hóa với Data Throughput Accelerator Skill, việc định vị chính xác nút thắt cổ chai quyết định 90% sự thành bại của dự án. Có một chi tiết thú vị là hầu hết mọi người đều đổ lỗi cho đường truyền mạng khi thấy pipeline chạy chậm. Tuy nhiên, qua nhiều lần phân tích thực tế, tôi nhận thấy điểm nghẽn thực sự lại nằm ở quá trình chuyển đổi cấu trúc dữ liệu hoặc cơ chế ghi ghi nhận (commit) của kho dữ liệu đích. Để triển khai Data Throughput Accelerator Skill hiệu quả, chúng ta phải phân biệt rõ ràng 6 khía cạnh hiệu năng cốt lõi sau đây.
- Tốc độ trích xuất nguồn (Source Extraction Speed): Tốc độ đọc dữ liệu thô từ hệ thống nguồn (Database, API, File Storage) mà không gây ảnh hưởng đến hiệu năng vận hành trực tiếp của nguồn đó.
- Tốc độ truyền tải mạng (Network Transfer Speed): Khả năng di chuyển các gói tin qua lại giữa môi trường nguồn và môi trường đích, bao gồm cả các yếu tố về nén dữ liệu và băng thông.
- Tốc độ ghi kho dữ liệu (Warehouse Load Speed): Hiệu năng lưu trữ thực tế tại đích đến, phụ thuộc rất nhiều vào cơ chế ghi đè, nối tiếp hoặc phân vùng bảng.
- Tốc độ biến đổi dữ liệu (Transform Speed): Thời gian cần thiết để thực hiện các thao tác làm sạch, ánh xạ, chuẩn hóa và tổng hợp dữ liệu trước khi đưa vào bảng đích.
- Độ tươi mới của bảng phục vụ (Serving-Table Freshness): Thời gian trễ từ lúc dữ liệu phát sinh ở nguồn cho đến khi người dùng cuối hoặc ứng dụng có thể truy vấn được từ bảng đích.
- Sự tăng trưởng của phần đuôi dữ liệu trực tiếp (Live Tail Growth): Lượng dữ liệu mới liên tục đổ về trong lúc các tác vụ xử lý lịch sử hoặc backfill đang diễn ra.
Hệ thống Data Throughput Accelerator Skill đòi hỏi chúng ta phải kiểm soát chặt chẽ mối liên hệ giữa các điểm nghẽn này. Nói một cách đơn giản, một pipeline có thể chạy rất “nhanh” về mặt lý thuyết, nhưng nó vẫn bị đánh giá là chậm trễ nếu tốc độ nạp dữ liệu mới chậm hơn tốc độ phát sinh của phần đuôi trực tiếp (live tail growth). Đây là trạng thái mất cân bằng kinh điển mà các giải pháp Data Throughput Accelerator Skill hướng tới giải quyết triệt để thông qua việc tối ưu hóa catch-up window.
7 Nguyên Tắc Vàng Của Data Throughput Accelerator Skill
Sau khi đã định vị chính xác vị trí của điểm nghẽn hiệu năng, chúng ta sẽ áp dụng các heuristics cốt lõi của Data Throughput Accelerator Skill để giải phóng băng thông xử lý. Các nguyên lý này tập trung vào việc giảm thiểu chi phí di chuyển dữ liệu, tận dụng tối đa sức mạnh tính toán bản địa và thiết lập cơ chế kiểm soát tiến trình chặt chẽ.
Áp dụng Data Throughput Accelerator Skill vào dự án thực tế yêu cầu tuân thủ nguyên tắc di chuyển mã nguồn hoặc tác vụ tính toán đến nơi chứa dữ liệu, thay vì tải dữ liệu khổng lồ về máy chủ ứng dụng để xử lý. Việc này giúp tiết kiệm tối đa tài nguyên mạng và tận dụng được năng lực phân tích song song cực mạnh của các kho dữ liệu hiện đại như BigQuery, Snowflake hay Redshift.
Nguyên tắc thứ hai của Data Throughput Accelerator Skill là ưu tiên sử dụng các cú pháp quét (scans), gộp (joins) và nối tiếp dữ liệu (appends) nguyên bản của kho dữ liệu. Việc thực hiện các câu lệnh SQL trực tiếp trên các tệp dữ liệu lớn đã được tải lên vùng lưu trữ tạm (staging) luôn nhanh hơn nhiều so với việc phân tích từng dòng dữ liệu bằng mã nguồn ngoại vi. Đây là nền tảng cốt lõi giúp Data Throughput Accelerator Skill duy trì tốc độ xử lý hàng triệu dòng mỗi giây.
Với Data Throughput Accelerator Skill, cơ chế manifest và checkpoint đóng vai trò cực kỳ then chốt. Để minh họa rõ hơn cách thiết lập một cấu trúc bảng lưu trữ tạm và cơ chế manifest phục vụ cho quá trình kiểm soát tiến trình, hãy xem ví dụ SQL khởi tạo dưới đây:
CREATE TABLE data_ingestion_manifest (
file_name VARCHAR(255) PRIMARY KEY,
ingested_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
status VARCHAR(50),
record_count INT,
checksum VARCHAR(64)
);
CREATE TABLE staging_events (
event_id VARCHAR(100),
user_id VARCHAR(100),
event_type VARCHAR(50),
event_time TIMESTAMP,
payload TEXT
);Bằng việc duy trì bảng `data_ingestion_manifest` như trên, Data Throughput Accelerator Skill cho phép hệ thống nhanh chóng bỏ qua các tệp tin hoặc phân vùng dữ liệu đã được xử lý thành công trước đó. Mỗi khi pipeline bị gián đoạn giữa chừng do sự cố hạ tầng, hệ thống có thể tái khởi động ngay lập tức tại điểm checkpoint gần nhất mà không phải chạy lại toàn bộ tiến trình từ đầu.
Trong kiến trúc Data Throughput Accelerator Skill, phân vùng (partitioning) và nhóm cụm dữ liệu (clustering) cần phải được thiết kế tương thích hoàn toàn với hành vi đọc dữ liệu của người dùng cuối và cơ chế nối tiếp của hệ thống. Nếu bạn phân vùng theo ngày nhưng người dùng luôn truy vấn theo ID người dùng, toàn bộ lợi thế về tốc độ của Data Throughput Accelerator Skill sẽ bị triệt tiêu hoàn toàn.
Một khía cạnh khác của Data Throughput Accelerator Skill là việc gộp nhóm (batching) các tệp nhỏ, các yêu cầu API và các tác vụ ghi dữ liệu. Thay vì gửi hàng ngàn truy vấn ghi đơn lẻ, chúng ta cần gom chúng lại thành các lô lớn từ vài chục ngàn đến hàng trăm ngàn bản ghi. Cơ chế này giúp giảm tải đáng kể chi phí thiết lập kết nối và tối ưu hóa tài nguyên phần cứng cực kỳ hiệu quả.
Dưới đây là một đoạn mã Python đơn giản minh họa cách chia nhỏ dữ liệu thành các lô nhỏ để thực hiện ghi hàng loạt một cách tối ưu nhất trong hệ thống Data Throughput Accelerator Skill:
def generate_data_batches(records, batch_size=5000):
"""Chia nhỏ danh sách dữ liệu thành các lô xử lý tối ưu"""
batch = []
for record in records:
batch.append(record)
if len(batch) == batch_size:
yield batch
batch = []
if batch:
yield batchQuy tắc bất di bất dịch cuối cùng của Data Throughput Accelerator Skill là tính bất biến (idempotency) của các thao tác ghi dữ liệu. Mọi hành động nạp thông tin phải có khả năng chạy đi chạy lại nhiều lần mà không làm nhân đôi bản ghi hay làm sai lệch kết quả cuối cùng. Chúng ta có thể đạt được điều này thông qua việc sử dụng các khóa duy nhất (unique keys), bảng tạm có thể thay thế hoàn toàn hoặc sử dụng cú pháp MERGE trong cơ sở dữ liệu để vừa cập nhật vừa chèn mới dữ liệu một cách an toàn.
Quy Trình 7 Bước Triển Khai Data Throughput Accelerator Skill
Để đưa các nguyên lý trên vào thực tế vận hành, chúng ta cần tuân thủ một quy trình 7 bước nghiêm ngặt của Data Throughput Accelerator Skill. Quy trình này đảm bảo mỗi sự thay đổi về mặt kiến trúc đều được đo lường, thử nghiệm và kiểm chứng một cách khoa học trước khi đưa vào môi trường sản xuất thực tế.
Bước 1 của quy trình Data Throughput Accelerator Skill là đọc và phân tích kỹ lưỡng các ràng buộc về hợp đồng dữ liệu giữa nguồn,ích và hệ thống manifest hiện tại. Việc hiểu rõ cấu trúc schema và các ràng buộc về kiểu dữ liệu giúp ngăn ngừa các lỗi phân tích cú pháp phát sinh giữa chừng làm gián đoạn pipeline.
Ở Bước 2, Data Throughput Accelerator Skill yêu cầu đo lường chính xác lượng backlog hiện tại của hệ thống. Chúng ta cần thu thập các số liệu chi tiết bao gồm: số lượng tệp tin ngoại vi chưa xử lý, số dòng dữ liệu trong manifest, số dòng thô trong staging, số dòng đã được xử lý trong bảng derived, khoảng thời gian tối đa và tối thiểu của timestamp, và tỷ lệ tăng trưởng của dữ liệu mới.
Bước 3 trong Data Throughput Accelerator Skill là thực hiện một phiên catch-up an toàn hoặc chạy một bài kiểm định hiệu năng (benchmark) trên một tập mẫu dữ liệu nhỏ. Việc này giúp thiết lập các chỉ số cơ sở về mặt tốc độ xử lý thô và phát hiện sớm các xung đột phần cứng hay giới hạn băng thông mạng ở giai đoạn đầu.
Tiến hành Bước 4 của Data Throughput Accelerator Skill bằng cách so sánh các biến thể cấu hình khác nhau để tìm ra điểm cân bằng tối ưu. Các biến số cần được đưa lên bàn cân bao gồm kích thước lô dữ liệu (batch size), số lượng luồng xử lý song song (worker count), tối ưu hóa cú pháp SQL, phương pháp gộp nhóm tệp tin, cấu trúc của bảng staging và cơ chế cập nhật manifest.
Hãy xem xét một ví dụ thực tế về đoạn mã Python thực hiện việc so sánh tốc độ xử lý giữa các cấu hình worker khác nhau để đưa ra quyết định tối ưu nhất cho Data Throughput Accelerator Skill:
import time
from concurrent.futures import ThreadPoolExecutor
def mock_process_file(file_name):
# Giả lập thời gian xử lý tệp dữ liệu thô
time.sleep(0.1)
return True
def run_pipeline_benchmark(files, workers=4):
start_time = time.time()
with ThreadPoolExecutor(max_workers=workers) as executor:
results = list(executor.map(mock_process_file, files))
duration = time.time() - start_time
print(f"Workers: {workers} - Processed {len(files)} files in {duration:.2f}s")
return durationĐến Bước 5, Data Throughput Accelerator Skill hướng dẫn chỉ thúc đẩy và lựa chọn phương án xử lý có tốc độ cao nhất nhưng phải đảm bảo tuyệt đối tính nhất quán về số lượng bản ghi và mốc thời gian tối đa (max timestamps). Một giải pháp chạy nhanh gấp mười lần nhưng làm mất mát dữ liệu hoặc sai lệch số liệu tài chính sẽ ngay lập tức bị loại bỏ khỏi quy trình.
Bước 6 của Data Throughput Accelerator Skill yêu cầu đóng gói giải pháp tối ưu thành một công cụ dòng lệnh (CLI), một tác vụ được lập lịch định kỳ (cron job), một quy trình tự động hóa (workflow) trên các công cụ như Airflow, Prefect hoặc một tài liệu hướng dẫn vận hành chi tiết (runbook) để đội ngũ kỹ thuật có thể dễ dàng bảo trì và tái sử dụng.
Cuối cùng, Bước 7 của Data Throughput Accelerator Skill là chạy lại toàn bộ hệ thống đối soát dữ liệu sau khi tiến trình đã được đóng gói và thực thi hoàn tất. Bước này giúp chứng minh bằng con số thực tế rằng hệ thống đã hoạt động chính xác và không có bất kỳ sai sót nào xảy ra trong suốt quá trình tăng tốc luồng dữ liệu.
Kiểm Thử Hiệu Năng Trong Data Throughput Accelerator Skill
Trong khuôn khổ Data Throughput Accelerator Skill, các kịch bản kiểm thử hiệu năng đóng vai trò cực kỳ quan trọng để đảm bảo pipeline hoạt động ổn định lâu dài dưới áp lực dữ liệu tăng đột biến. Chúng ta không chỉ kiểm tra hệ thống trong điều kiện lý tưởng, mà còn phải mô phỏng các tình huống lỗi mạng, mất kết nối cơ sở dữ liệu đích, hoặc tệp tin nguồn bị hỏng cấu trúc giữa chừng.
Khi thực thi Data Throughput Accelerator Skill trên thực tế, việc tích hợp các bài kiểm tra tự động là một phương pháp tiếp cận hiệu quả để xác minh tính nhất quán của dữ liệu. Bạn có thể tham khảo thêm các nguyên tắc tương tự tại bài viết về kiểm thử web bằng AI Agent để có thêm góc nhìn về quy trình tự động hóa kiểm định. Trong phát triển hệ thống dữ liệu, việc kiểm thử tự động giúp phát hiện ra các sai lệch logic trước khi chúng gây ảnh hưởng đến dữ liệu sản xuất.
Bên cạnh đó, việc hiểu rõ các yêu cầu về mặt dữ liệu và hành vi của người dùng cuối cũng đóng vai trò then chốt trong việc thiết kế các chỉ số đo lường hiệu năng của Data Throughput Accelerator Skill. Các kỹ thuật phân tích được đề cập trong hướng dẫn về nghiên cứu khách hàng có thể được áp dụng ngược lại để phân tích hành vi truy cập dữ liệu của các phòng ban trong doanh nghiệp, từ đó tối ưu hóa các phân vùng dữ liệu một cách chính xác nhất.
Đo Lường Kết Quả Data Throughput Accelerator Skill Với Khung Hạch Toán
Mỗi báo cáo đối soát của Data Throughput Accelerator Skill là minh chứng không thể chối cãi cho hiệu năng và tính chính xác của hệ thống. Điều này giúp các bên liên quan và kỹ sư vận hành có thể ngay lập tức kiểm tra tính toàn vẹn của dữ liệu sau mỗi chu kỳ chạy. Báo cáo này cần hiển thị rõ ràng số lượng tệp tin đầu vào, số dòng dữ liệu thô được thêm mới, số dòng phái sinh được tạo ra, lượng dữ liệu còn tồn đọng và tổng thời gian thực thi.
Dưới đây là một ví dụ mẫu về khối báo cáo đối soát tiêu chuẩn của hệ thống Data Throughput Accelerator Skill khi hoàn thành một tiến trình xử lý lớn:
Data throughput result:
- Source files discovered: 294
- Files processed this run: 294
- Raw rows added: 9,683,598
- Derived rows added: 8,917,585
- Remaining tail: 24 files at readback time
- Runtime: 38.7s
- Correctness gate: manifest counts and table max timestamps matchNhìn vào khối báo cáo trên, bất kỳ kỹ sư nào cũng có thể nhanh chóng xác nhận rằng cổng kiểm soát tính chính xác (Correctness gate) của Data Throughput Accelerator Skill đã được thông qua thành công nhờ sự khớp số giữa số lượng dòng dữ liệu thô và mốc thời gian tối đa của bảng đích. Đây là minh chứng rõ ràng nhất cho thấy hệ thống đã hoạt động đúng thiết kế.
5 Rào Chắn Bảo Vệ Hệ Thống Data Throughput Accelerator Skill
Khi theo đuổi mục tiêu tăng tốc độ xử lý dữ liệu với Data Throughput Accelerator Skill, các kỹ sư rất dễ rơi vào cái bẫy cắt giảm các bước kiểm tra an toàn hoặc bỏ qua các lỗi nhỏ để làm cho các chỉ số hiệu năng trông đẹp đẽ hơn. Để ngăn ngừa xu hướng tiêu cực này, Data Throughput Accelerator Skill thiết lập 5 rào chắn bảo vệ hệ thống cực kỳ nghiêm ngặt mà bất kỳ ai cũng không được phép vi phạm.
Rào chắn thứ nhất trong Data Throughput Accelerator Skill: Tuyệt đối không xóa hoặc chỉnh sửa dữ liệu thô (raw data) trên hệ thống lưu trữ chỉ để làm cho các chỉ số đo lường hiệu năng của pipeline trông có vẻ nhanh hơn. Dữ liệu thô là tài sản vô giá và là nguồn đối chiếu duy nhất khi có sự cố phát sinh. Việc xóa bỏ dữ liệu thô trái phép sẽ làm mất đi khả năng khôi phục và kiểm toán hệ thống.
Rào chắn thứ hai của Data Throughput Accelerator Skill: Không bao giờ được phép bỏ qua các tệp tin hoặc bản ghi bị lỗi một cách âm thầm. Mọi lỗi phát sinh trong quá trình đọc, chuyển đổi hoặc ghi dữ liệu đều phải được ghi nhận rõ ràng vào nhật ký lỗi và gửi cảnh báo đến đội ngũ vận hành. Các tệp lỗi cần được di chuyển vào một thư mục cách ly (quarantine) để phân tích thủ công sau đó.
Rào chắn thứ ba thuộc Data Throughput Accelerator Skill: Không được trộn lẫn trạng thái của quá trình nạp dữ liệu lịch sử (backfill) với dữ liệu thực tế đang phát sinh trực tiếp (live-tail freshness). Việc chạy song song hai tiến trình này mà không có cơ chế phân tách rõ ràng sẽ dẫn đến tình trạng tranh chấp tài nguyên và làm giảm nghiêm trọng độ tươi mới của dữ liệu phục vụ kinh doanh hiện tại.
Rào chắn thứ tư trong Data Throughput Accelerator Skill: Không công nhận một pipeline là hoàn thành cho đến khi có sự thống nhất hoàn toàn giữa các bảng dữ liệu đích và hệ thống manifest đối soát. Quá trình kiểm tra chéo này phải được thực hiện tự động ở cuối mỗi phiên chạy để đảm bảo không có dòng dữ liệu nào bị thất thoát trong quá trình xử lý.
Rào chắn thứ năm của Data Throughput Accelerator Skill: Đối với các hệ thống xử lý dữ liệu tài chính, y tế, dữ liệu có quy định kiểm soát pháp lý hoặc ảnh hưởng trực tiếp đến khách hàng, bắt buộc phải bảo tồn đầy đủ các bằng chứng chạy lại (replay evidence) và thiết lập các cổng phê duyệt thủ công (approval gates) trước khi cập nhật dữ liệu vào bảng chính thức.
Lưu Ý Khi Thiết Kế Hệ Thống Data Throughput Accelerator Skill Quy Mô Lớn
Khi thiết kế các hệ thống dữ liệu quy mô lớn theo nguyên lý Data Throughput Accelerator Skill, việc phối hợp đồng bộ giữa các kỹ sư dữ liệu và kiến trúc sư hệ thống là chìa khóa để duy trì sự ổn định. Mỗi quyết định thay đổi cấu trúc bảng hay lựa chọn công nghệ đều có thể tạo ra những tác động dây chuyền đến các hệ thống báo cáo phía sau. Hãy tham khảo tài liệu chính thức của Apache Spark Documentation hoặc tài liệu tối ưu hóa của Google BigQuery Docs để nắm vững các kỹ thuật phân vùng bảng nâng cao.
Ngoài ra, việc bảo mật thông tin và mã hóa dữ liệu nhạy cảm trong suốt quá trình di chuyển qua lại giữa các phân vùng mạng trong mô hình Data Throughput Accelerator Skill cũng cần được đặc biệt lưu ý. Bạn có thể tham khảo thêm tài liệu của AWS Glue ETL Service để tìm hiểu các phương thức bảo mật luồng dữ liệu trên đám mây theo các tiêu chuẩn quốc tế hiện hành.
Cuối cùng, hãy luôn nhớ rằng hiệu năng của hệ thống Data Throughput Accelerator Skill không phải là một đích đến cố định, mà là một hành trình tối ưu hóa liên tục. Những thiết kế hoạt động tốt ở quy mô hôm nay hoàn toàn có thể trở thành điểm nghẽn của ngày mai khi lượng dữ liệu tăng trưởng vượt bậc. Việc duy trì các thói quen đo lường định kỳ và đối soát số liệu chặt chẽ là cách tốt nhất để bảo vệ hệ thống dữ liệu của bạn trước mọi biến động.
Kết Luận Về Data Throughput Accelerator Skill Và Lời Khuyên Vận Hành
Áp dụng kỹ thuật Data Throughput Accelerator Skill vào hệ thống là một bước đi chiến lược giúp doanh nghiệp giải quyết triệt để bài toán hiệu năng luồng dữ liệu lớn. Bằng cách tuân thủ các nguyên tắc thiết kế bất biến, tối ưu hóa điểm nghẽn đúng chỗ và thiết lập hệ thống manifest đối soát chặt chẽ, bạn sẽ xây dựng được một hạ tầng dữ liệu vừa mạnh mẽ về tốc độ, vừa vững chắc về độ tin cậy.
Lời khuyên cuối cùng của tôi dành cho bạn khi triển khai Data Throughput Accelerator Skill là hãy bắt đầu tối ưu hóa từ những bước nhỏ nhất. Đừng cố gắng thay đổi toàn bộ kiến trúc pipeline trong một đêm. Hãy áp dụng quy trình 7 bước đã nêu để đo lường, thử nghiệm và tối ưu hóa từng phần nhỏ, tích lũy các cải tiến hiệu năng một cách bền vững và an toàn cho doanh nghiệp của bạn.