Nhờ MySQL Patterns Skill, xây dựng một hệ thống cơ sở dữ liệu hoạt động ổn định ở môi trường production luôn là thử thách lớn đối với mọi lập trình viên backend. Khi quy mô dữ liệu tăng từ vài nghìn dòng lên hàng triệu, rồi hàng trăm triệu dòng, các thiết kế sơ sài ban đầu sẽ nhanh chóng bộc lộ điểm yếu. Lúc này, việc hiểu rõ và áp dụng đúng các MySQL patterns (mẫu thiết kế MySQL) tiêu chuẩn trở thành yếu tố quyết định để duy trì hiệu năng, bảo đảm tính toàn vẹn dữ liệu và tối ưu chi phí vận hành hệ thống.
Thực tế thì thiết kế cơ sở dữ liệu không chỉ đơn thuần là tạo bảng và định nghĩa các cột dữ liệu. Đó là cả một nghệ thuật cân bằng giữa cấu trúc schema (bằng MySQL Patterns Skill), chiến lược thiết lập index, kỹ thuật tối ưu hóa truy vấn và cơ chế quản lý giao dịch (transactions). Bài viết này sẽ phân tích chuyên sâu các khía cạnh cốt lõi của MySQL và MariaDB, từ đó cung cấp các mẫu thiết kế chuẩn chỉ được đúc kết từ kinh nghiệm vận hành thực tế tại các hệ thống lớn.
MySQL Patterns Skill: 1. Phân Biệt MySQL và MariaDB: Điểm Khởi Đầu Quan Trọng
Trước khi bắt tay vào thiết kế schema (bằng MySQL Patterns Skill) hay tối ưu hóa bất kỳ truy vấn nào, bước đầu tiên và quan trọng nhất là bạn phải xác định chính xác công cụ và phiên bản hệ quản trị cơ sở dữ liệu đang chạy.
Nhờ MySQL Patterns Skill, mặc dù MariaDB khởi đầu là một nhánh rẽ (fork) từ MySQL và duy trì khả năng tương thích ngược rất cao, hai hệ thống này đã phân kỳ đáng kể trong những phiên bản gần đây. Việc áp dụng sai cú pháp hoặc tính năng đặc thù của hệ thống này lên hệ thống kia có thể dẫn đến các lỗi cú pháp nghiêm trọng khi chạy migrations hoặc tệ hơn là gây treo lock ngoài ý muốn trên môi trường production.
Nhờ MySQL Patterns Skill, để nhận diện môi trường làm việc của mình, bạn có thể thực hiện chạy hai câu lệnh kiểm tra phiên bản quen thuộc dưới đây:
SELECT VERSION();
SHOW VARIABLES LIKE 'version_comment';Nhờ MySQL Patterns Skill, hãy chú ý đến kết quả trả về. Nếu chuỗi phiên bản chứa tên MariaDB, bạn đang làm việc với một công cụ có triết lý tối ưu hóa và các mở rộng SQL riêng biệt. Một trong những điểm khác biệt điển hình nhất liên quan đến cú pháp cập nhật dữ liệu trùng lặp (Upsert) qua câu lệnh ON DUPLICATE KEY UPDATE:
- Trong MySQL (đặc biệt từ phiên bản 8.0 trở lên): Việc sử dụng hàm
VALUES(column_name)để tham chiếu đến giá trị mới định chèn đã bị đưa vào danh sách cảnh báo lỗi thời (deprecated). MySQL khuyến khích lập trình viên chuyển sang sử dụng bí danh hàng (row aliases) thông qua cú pháp mới dạngINSERT INTO table VALUES (...) AS new_alias ON DUPLICATE KEY UPDATE col = new_alias.col. - Trong MariaDB: Hàm
VALUES(column_name)vẫn là cú pháp chính thức được hỗ trợ và khuyên dùng để tham chiếu giá trị mới. Việc viết code sử dụng bí danh hàng kiểu MySQL trên một hệ thống MariaDB sẽ trực tiếp ném ra lỗi cú pháp SQL và phá hỏng quy trình xử lý của ứng dụng. Do đó, nếu bạn đang xây dựng một codebase cần chạy trên cả hai hệ thống này, sử dụng hàmVALUES()cũ vẫn là giải pháp tương thích chéo an toàn nhất.
Nhờ MySQL Patterns Skill, một điểm phân kỳ kỹ thuật khác cần lưu ý là tính năng xử lý hàng đợi với mệnh đề khóa SKIP LOCKED. Mệnh đề này cực kỳ hữu ích khi xây dựng các tác vụ dạng worker lấy dữ liệu từ bảng để xử lý tuần tự.
Nhờ MySQL Patterns Skill, khi sử dụng SKIP LOCKED, MySQL sẽ bỏ qua các hàng đang bị khóa bởi transaction khác và trả về ngay lập tức các hàng tự do tiếp theo mà không bắt luồng xử lý phải chờ đợi. Tuy nhiên, tính năng này có thể trả về một kết quả không nhất quán về mặt dữ liệu tổng thể, do đó tuyệt đối không được dùng nó cho các truy vấn kế toán, tài chính hoặc kiểm tra tính toàn vẹn dữ liệu nhạy cảm.
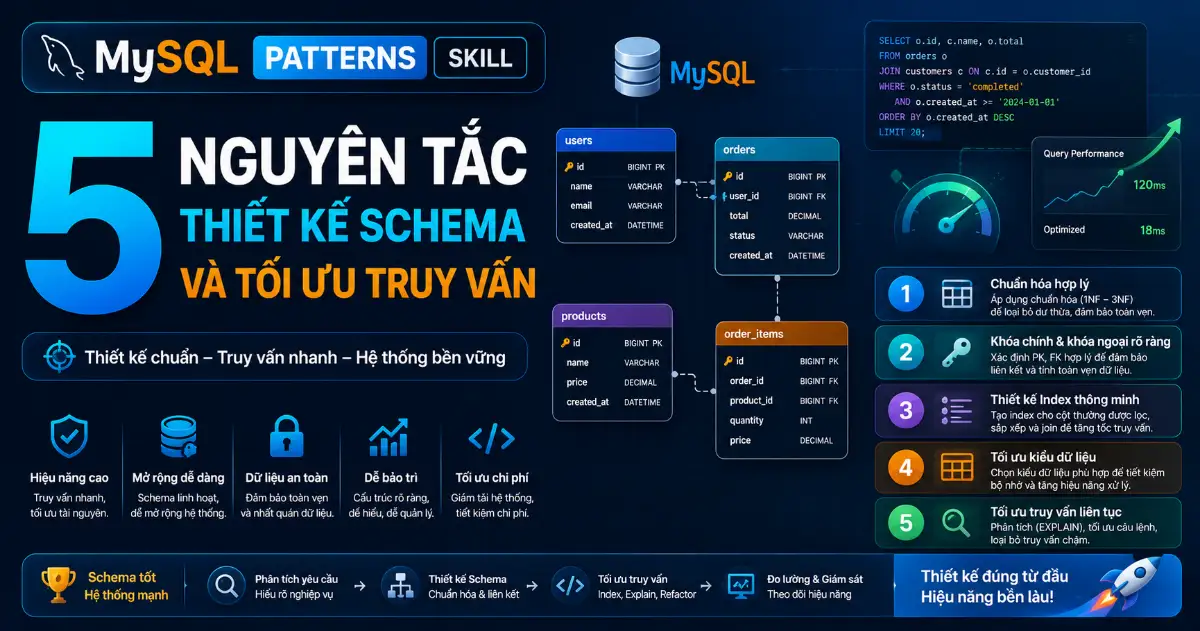
2. Thiết Kế Schema Mặc Định Chuẩn Production
Một thiết kế schema (bằng MySQL Patterns Skill) MySQL tốt giống như phần móng vững chắc của một tòa nhà. Nếu thiết kế sai kiểu dữ liệu ngay từ đầu, bạn sẽ phải đối mặt với các đợt migration đau đớn khi bảng dữ liệu đã phình to lên hàng trăm gigabyte. Dưới đây là một cấu trúc bảng mẫu chuẩn dành cho việc lưu trữ thông tin đơn hàng, tích hợp đầy đủ các nguyên tắc thiết kế schema MySQL tối ưu:
CREATE TABLE orders (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
account_id BIGINT UNSIGNED NOT NULL,
status VARCHAR(32) NOT NULL,
total DECIMAL(15, 2) NOT NULL,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
deleted_at DATETIME NULL,
PRIMARY KEY (id),
KEY idx_orders_account_status_created (account_id, status, created_at),
KEY idx_orders_active (account_id, deleted_at)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;Nhờ MySQL Patterns Skill, hãy phân tích chi tiết từng quyết định thiết kế trong cấu trúc bảng trên:
Nhờ MySQL Patterns Skill, Khóa chính đại diện (Surrogate Primary Keys): Sử dụng kiểu dữ liệu BIGINT UNSIGNED kết hợp thuộc tính AUTO_INCREMENT. Tránh tuyệt đối việc sử dụng kiểu INT thông thường (giới hạn ở khoảng 2.1 tỷ bản ghi) cho các bảng chứa dữ liệu giao dịch hoặc log. Thực tế đã ghi nhận rất nhiều sự cố hệ thống lớn bị sập hoàn toàn chỉ vì cạn kiệt không gian số ID của kiểu dữ liệu INT. Việc sử dụng BIGINT chỉ tốn thêm 4 byte cho mỗi bản ghi nhưng mang lại sự an tâm tuyệt đối về khả năng mở rộng.
Nhờ MySQL Patterns Skill, Dữ liệu tiền tệ và số lượng chính xác: Cột total lưu trữ tổng tiền được khai báo bằng kiểu DECIMAL(15, 2). Trong các bài toán liên quan đến tiền bạc, tính toán tài chính, tuyệt đối không bao giờ được phép sử dụng kiểu dữ liệu số thực dấu phẩy động như FLOAT hoặc DOUBLE. Các kiểu dữ liệu số thực này hoạt động dựa trên cơ chế xấp xỉ nhị phân, dẫn đến hiện tượng sai số làm tròn tích lũy sau nhiều phép toán cộng trừ nhân chia – một thảm họa đối với sổ sách kế toán.
Nhờ MySQL Patterns Skill, Mã hóa ký tự chuẩn hóa (Character Set & Collation): Khai báo bảng sử dụng bộ mã ký tự utf8mb4 cùng collation utf8mb4_unicode_ci. Bộ mã ký tự utf8 cũ của MySQL (thực chất là utf8mb3) chỉ hỗ trợ tối đa 3 byte cho mỗi ký tự, dẫn đến việc không thể lưu trữ các ký tự mở rộng như biểu tượng cảm xúc (emoji) hoặc một số chữ Hán cổ. Việc cố tình chèn các ký tự này vào bảng utf8 cũ sẽ khiến MySQL ném ra lỗi hoặc cắt cụt dữ liệu của người dùng.
Nhờ MySQL Patterns Skill, Thời gian ứng dụng (Timestamps): Sử dụng kiểu dữ liệu DATETIME và quản lý múi giờ hoàn toàn ở tầng ứng dụng (thông thường là lưu trữ múi giờ UTC). Mặc dù kiểu dữ liệu TIMESTAMP tự động chuyển đổi múi giờ dựa trên múi giờ của kết nối MySQL server, nó lại bị giới hạn bởi vấn đề năm 2038 (giới hạn 32-bit của Epoch time). Kiểu dữ liệu DATETIME cung cấp dải lưu trữ rộng hơn rất nhiều và giúp hành vi của ứng dụng trở nên tường minh, dễ dự đoán hơn khi phân phối dịch vụ trên nhiều quốc gia khác nhau.
Nhờ MySQL Patterns Skill, Xóa mềm (Soft Deletes): Khai báo cột deleted_at DATETIME NULL để hỗ trợ tính năng xóa mềm dữ liệu mà vẫn giữ lại lịch sử. Vấn đề lớn nhất khi triển khai xóa mềm là các truy vấn thông thường của hệ thống sẽ phải liên tục lọc thêm điều kiện WHERE deleted_at IS NULL. Nếu không có các index phù hợp chứa cột này (như index composite idx_orders_active ở trên), cơ sở dữ liệu sẽ phải quét toàn bộ bảng (table scan) rất tốn tài nguyên.
Dưới đây là bảng tổng hợp các khuyến nghị thiết kế schema (bằng MySQL Patterns Skill) nhanh để bạn dễ dàng tra cứu khi cần thiết:
| Trường hợp sử dụng | Nên chọn | Nên tránh |
|---|---|---|
| Khóa chính tự tăng | BIGINT UNSIGNED AUTO_INCREMENT | INT (giới hạn 2 tỷ dòng) |
| Khóa tìm kiếm dạng UUID | BINARY(16) kèm hàm chuyển đổi | VARCHAR(36) làm khóa chính trên bảng nóng |
| Tiền tệ và số lượng chính xác | DECIMAL(p, s) | FLOAT hoặc DOUBLE (sai số làm tròn) |
| Văn bản tiếng Việt & Emoji | utf8mb4 kèm utf8mb4_unicode_ci | utf8 hoặc latin1 mặc định |
| Thời gian lưu trữ | DATETIME quản lý UTC bởi App | Giả định DATETIME tự lưu múi giờ |
| Trạng thái có thể mở rộng | Bảng liên kết hoặc VARCHAR giới hạn | ENUM (gây khóa bảng khi thay đổi giá trị) |
3. Chiến Lược Thiết Kế Index trong MySQL
Nhờ MySQL Patterns Skill, để tối ưu hóa hiệu năng truy vấn dữ liệu, việc hiểu rõ cách thức hoạt động của index trong MySQL (đặc biệt là công cụ lưu trữ mặc định InnoDB) là bắt buộc. InnoDB tổ chức dữ liệu dưới dạng các bảng chỉ mục dạng cây B+ (B+ Tree Indexes). Điều này nghĩa là thứ tự của các cột trong một index phức hợp (composite index) đóng vai trò quyết định đến việc câu lệnh SQL của bạn có sử dụng được index đó hay không.
Nhờ MySQL Patterns Skill, nguyên tắc vàng khi sắp xếp thứ tự các cột trong một index composite là: **Đặt các cột có toán tử so sánh bằng (equality) lên trước, sau đó mới đến các cột sử dụng toán tử so sánh khoảng (range) hoặc dùng để sắp xếp dữ liệu (sort/order by)**.
Nhờ MySQL Patterns Skill, hãy xem xét ví dụ cụ thể sau đây với index idx_orders_account_status_created được định nghĩa trên ba cột (account_id, status, created_at):
SELECT id, total
FROM orders
WHERE account_id = 456
AND status = 'pending'
AND created_at >= '2025-01-01 00:00:00'
ORDER BY created_at DESC
LIMIT 50;Nhờ MySQL Patterns Skill, trong câu lệnh này, MySQL sẽ sử dụng index để thực hiện lọc nhanh chóng các bản ghi có account_id = 456 (so sánh bằng), tiếp tục lọc sâu qua status = 'pending' (so sánh bằng), và sau đó thực hiện quét khoảng giá trị trên cột created_at. Do thứ tự các cột trên index trùng khớp hoàn hảo với cấu trúc lọc và sắp xếp của câu lệnh, MySQL sẽ không cần phải thực hiện bất kỳ thao tác sắp xếp phụ nào trên bộ nhớ (filesort) mà vẫn trả về kết quả cực kỳ nhanh chóng.
Nhờ MySQL Patterns Skill, để đánh giá xem một câu truy vấn có đang chạy hiệu quả hay không, bạn hãy luôn sử dụng công cụ phân tích truy vấn EXPLAIN đi kèm trước câu lệnh SQL:
EXPLAIN
SELECT id, total
FROM orders
WHERE account_id = 123 AND status = 'pending'
ORDER BY created_at DESC
LIMIT 50;Nhờ MySQL Patterns Skill, khi đọc kết quả trả về từ lệnh EXPLAIN, hãy chú ý đến các tín hiệu cảnh báo rủi ro hiệu năng sau đây để kịp thời tối ưu hóa:
| Tên cột kết quả | Tín hiệu rủi ro | Ý nghĩa và hành động cần thiết |
|---|---|---|
type | ALL | Quét toàn bộ bảng (Table Scan). Rất nguy hiểm nếu bảng lớn. Cần thêm index gấp. |
key | NULL | Không có index nào được sử dụng cho truy vấn này. |
rows | Giá trị quá lớn | Số lượng hàng dự kiến phải quét quá nhiều để trả về kết quả. Cần thu hẹp điều kiện lọc. |
Extra | Using temporary hoặc Using filesort | MySQL phải tạo bảng tạm trên đĩa/bộ nhớ hoặc phải tự sắp xếp dữ liệu lại. Rất tốn CPU. |
Nhờ MySQL Patterns Skill, một điểm lưu ý quan trọng là tránh việc thêm index một cách mù quáng cho mọi cột trong bảng. Mỗi index được tạo thêm đồng nghĩa với việc MySQL phải thực hiện thêm các thao tác ghi dữ liệu vào cây chỉ mục mỗi khi có lệnh INSERT, UPDATE, hoặc DELETE. Hơn nữa, quá nhiều index sẽ làm tăng kích thước file sao lưu (backup), kéo dài thời gian chạy migration và gây áp lực lớn lên bộ nhớ đệm Buffer Pool của InnoDB.
4. Tối Ưu Truy Vấn MySQL Với Kỹ Thuật Nâng Cao
Nhờ MySQL Patterns Skill, trong quá trình phát triển ứng dụng, có hai bài toán truy vấn kinh điển thường xuyên gây ra các vấn đề về hiệu năng và tranh chấp khóa (locking): xử lý Upsert (chèn hoặc cập nhật) và xử lý phân trang dữ liệu lớn (pagination).
MySQL Patterns Skill: Kỹ thuật xử lý Upsert tối ưu
Nhờ MySQL Patterns Skill, mẫu thiết kế Upsert cho phép bạn chèn một bản ghi mới vào hệ thống, nhưng nếu bản ghi đó đã tồn tại (dựa trên khóa chính hoặc khóa duy nhất Unique Key), hệ thống sẽ chuyển sang chế độ cập nhật dữ liệu. Để đảm bảo ứng dụng có thể hoạt động trơn tru trên cả MySQL lẫn MariaDB, bạn nên sử dụng cú pháp chuẩn hóa sau:
INSERT INTO user_settings (user_id, setting_key, setting_value)
VALUES (101, 'theme', 'dark')
ON DUPLICATE KEY UPDATE
setting_value = VALUES(setting_value),
updated_at = CURRENT_TIMESTAMP;Nhờ MySQL Patterns Skill, trong khi đó, nếu bạn chắc chắn 100% rằng cơ sở dữ liệu đích của mình là MySQL phiên bản mới, cú pháp sử dụng bí danh hàng dưới đây là lựa chọn được khuyên dùng để tránh các cảnh báo lỗi thời:
INSERT INTO user_settings (user_id, setting_key, setting_value)
VALUES (101, 'theme', 'dark') AS new_data
ON DUPLICATE KEY UPDATE
setting_value = new_data.setting_value,
updated_at = CURRENT_TIMESTAMP;MySQL Patterns Skill: Phân trang hiệu năng cao với Keyset Pagination
Nhờ MySQL Patterns Skill, hầu hết các ứng dụng ban đầu đều sử dụng phương pháp phân trang truyền thống bằng mệnh đề LIMIT Offset, Count. Ví dụ, câu lệnh LIMIT 100000, 50 yêu cầu MySQL phải quét qua toàn bộ 100,000 bản ghi đầu tiên, bỏ chúng đi, và chỉ lấy ra 50 bản ghi tiếp theo. Khi giá trị offset tăng lên lớn, tốc độ phản hồi của trang web sẽ chậm dần một cách rõ rệt, thậm chí gây treo luồng xử lý của cơ sở dữ liệu.
Nhờ MySQL Patterns Skill, giải pháp tối ưu cho bài toán này là áp dụng **Keyset Pagination** (hay còn gọi là Cursor Pagination). Thay vì chỉ định số dòng cần bỏ qua, chúng ta sẽ lọc trực tiếp dựa trên giá trị của bản ghi cuối cùng của trang trước đó làm điểm neo dữ liệu:
SELECT id, name, created_at
FROM products
WHERE (created_at, id) < ('2025-01-15 12:00:00', 987)
ORDER BY created_at DESC, id DESC
LIMIT 50;Nhờ MySQL Patterns Skill, để câu lệnh lọc này chạy với tốc độ tuyệt đối, chúng ta bắt buộc phải khai báo một index phức hợp tương ứng làm bệ đỡ phía sau:
CREATE INDEX idx_products_created_id ON products (created_at, id);Nhờ MySQL Patterns Skill, nhờ cấu trúc index này, MySQL chỉ việc nhảy trực tiếp đến vị trí con trỏ của điểm neo dữ liệu trên cây B+ Tree và quét tuần tự ra đúng 50 bản ghi tiếp theo. Thời gian thực thi của câu lệnh phân trang lúc này sẽ luôn là hằng số (O(log N)) dù người dùng có đang lướt ở trang thứ nhất hay trang thứ một triệu đi chăng nữa.
5. Giao Dịch Và Dữ Liệu Phức Tạp: JSON và MySQL Transaction
Nhờ MySQL Patterns Skill, hệ sinh thái MySQL hiện đại cung cấp khả năng xử lý dữ liệu bán cấu trúc rất mạnh mẽ thông qua kiểu dữ liệu JSON, đồng thời duy trì các tiêu chuẩn ACID khắt khe thông qua hệ thống Transaction (giao dịch) của công cụ lưu trữ InnoDB.
MySQL Patterns Skill: Sử dụng và tối ưu hóa cột dữ liệu JSON
Nhờ MySQL Patterns Skill, mặc dù việc sử dụng cột JSON mang lại sự linh hoạt rất lớn trong việc lưu trữ các thuộc tính mở rộng của đối tượng (metadata, cấu hình tùy biến), bạn không nên lạm dụng nó cho các trường dữ liệu cần lọc, sắp xếp hoặc làm điều kiện kết hợp (JOIN) thường xuyên giữa các bảng. Một hạn chế lớn của JSON là MySQL không thể tạo index trực tiếp trên cấu trúc JSON nội bộ một cách thông thường.
Nhờ MySQL Patterns Skill, để khắc phục nhược điểm này và tối ưu hóa hiệu năng, bạn hãy tận dụng tính năng Cột được tạo tự động (Generated Column) của MySQL. Bằng cách định nghĩa một cột ảo tự động trích xuất dữ liệu từ trường JSON và thiết lập index trên cột ảo đó, bạn sẽ có được tốc độ truy vấn vượt trội:
CREATE TABLE events (
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
payload JSON NOT NULL,
event_type VARCHAR(64) GENERATED ALWAYS AS (JSON_UNQUOTE(JSON_EXTRACT(payload, '$.event_type'))) STORED,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
KEY idx_events_type (event_type)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;Từ khóa STORED chỉ thị cho MySQL lưu trữ vật lý giá trị trích xuất này trên đĩa cứng để thuận tiện cho việc tạo index B+ Tree. Nhờ đó, câu lệnh truy vấn lọc theo event_type dưới đây sẽ chạy cực kỳ nhanh mà không cần phải thực hiện phân tích cú pháp chuỗi JSON lúc chạy:
SELECT id, payload
FROM events
WHERE event_type = 'user_signup';Mẫu thiết kế hàng đợi giao dịch an toàn (Queue Transaction Pattern)
Khi bạn cần triển khai một hệ thống xử lý hàng đợi công việc đơn giản dựa trên cơ sở dữ liệu MySQL, việc xử lý tranh chấp giữa các worker đồng thời (race conditions) là vấn đề nan giải nhất. Mẫu thiết kế tối ưu dưới đây minh họa cách thức một worker có thể khóa và lấy ra một công việc trống để xử lý mà không sợ bị trùng lặp với các worker khác:
START TRANSACTION;
SELECT id, payload
FROM jobs
WHERE status = 'queued'
LIMIT 1
FOR UPDATE SKIP LOCKED;
-- Cap nhat trang thai cong viec vua nhan duoc
UPDATE jobs
SET status = 'processing',
updated_at = CURRENT_TIMESTAMP
WHERE id = @selected_job_id;
COMMIT;Sự kết hợp giữa FOR UPDATE (khóa độc quyền dòng dữ liệu) và SKIP LOCKED (bỏ qua các dòng đã bị worker khác khóa trước đó) đảm bảo rằng mỗi worker sẽ ngay lập tức nhận được một công việc riêng biệt mà không gặp phải tình trạng xếp hàng chờ đợi (lock wait lockups). Đây chính là mẫu thiết kế MySQL kinh điển giúp tăng tối đa hiệu năng xử lý song song trong các tác vụ bất đồng bộ của backend.
6. Kết Luận: Lời Khuyên Cho Hành Trình Vận Hành Cơ Sở Dữ Liệu
Học hỏi và áp dụng các MySQL patterns tiêu chuẩn không chỉ giúp nâng cao hiệu năng hệ thống hiện tại, mà còn giúp bảo vệ cơ sở dữ liệu của bạn trước những biến động về quy mô người dùng trong tương lai. Có một chi tiết thú vị là hầu hết các vấn đề về hiệu năng database trên môi trường thực tế không xuất phát từ bản thân công cụ MySQL, mà thường nằm ở các thiết kế schema thiếu kinh nghiệm hoặc các câu truy vấn viết sai cách làm quá tải Buffer Pool.
Nếu bạn hỏi mình đâu là lời khuyên quan trọng nhất, câu trả lời sẽ là: Hãy luôn đo lường trước khi đưa ra bất kỳ tối ưu hóa nào. Việc lạm dụng index, chia nhỏ bảng quá sớm (sharding) hoặc chuyển sang NoSQL mà không có số liệu chứng minh cụ thể chỉ làm tăng độ phức tạp của hệ thống mà không mang lại giá trị thực tế. Hãy xây dựng thói quen thường xuyên phân tích slow logs, sử dụng lệnh EXPLAIN như một bước bắt buộc trong quy trình code review, và quản lý các giao dịch một cách cẩn thận nhất.