
OpenAI đã chính thức giới thiệu GPT-5.5 – mô hình mới được đánh giá là thông minh và trực quan nhất hiện nay. Không chỉ dừng lại ở việc trả lời câu hỏi, GPT-5.5 còn có khả năng tự thực hiện các nhiệm vụ phức tạp, từ viết code, phân tích dữ liệu đến tự động hóa quy trình làm việc. Vậy GPT-5.5 là gì, có gì mới và khác biệt ra sao so với phiên bản trước? Hãy cùng tìm hiểu chi tiết trong bài viết dưới đây.
GPT-5.5 là gì?
GPT-5.5 là mô hình trí tuệ nhân tạo (AI) mới nhất do OpenAI phát hành vào ngày 23 tháng 4 năm 2026, được thiết kế cho các công việc phức tạp trong thế giới thực, bao gồm viết mã, nghiên cứu trực tuyến, phân tích thông tin, tạo tài liệu và bảng tính, cũng như di chuyển giữa nhiều công cụ để hoàn thành nhiệm vụ.
So với các mô hình trước đây, GPT-5.5 có khả năng hiểu nhiệm vụ sớm hơn, cần ít hướng dẫn hơn, sử dụng công cụ hiệu quả hơn, tự kiểm tra kết quả và tiếp tục thực hiện cho đến khi hoàn thành công việc.

Những cải tiến này đặc biệt mạnh trong các lĩnh vực như lập trình mang tính “agent”, sử dụng máy tính, công việc tri thức và nghiên cứu khoa học giai đoạn đầu – những lĩnh vực mà tiến bộ phụ thuộc vào khả năng suy luận theo ngữ cảnh và hành động theo thời gian.
GPT-5.5 mang lại bước tiến về trí tuệ mà không làm giảm tốc độ: các mô hình lớn hơn và mạnh hơn thường chậm hơn khi phục vụ, nhưng GPT-5.5 có độ trễ theo token tương đương GPT-5.4 trong thực tế, trong khi lại đạt mức độ thông minh cao hơn đáng kể. Ngoài ra, nó còn sử dụng ít token hơn đáng kể để hoàn thành cùng một tác vụ Codex, giúp vừa hiệu quả hơn vừa mạnh mẽ hơn.
GPT-5.5 có gì mới? 7 cải tiến quan trọng từ OpenAI
GPT-5.5 có gì mới? Dưới đây là 7 cải tiến quan trọng nhất mà OpenAI đã mang đến trong phiên bản này, phản ánh rõ hướng đi mới của thế hệ AI tiếp theo.
Một trong những thay đổi lớn nhất của GPT-5.5 là sự nâng cấp rõ rệt về khả năng hoạt động như một AI agent.
Thay vì chỉ trả lời câu hỏi theo từng lượt, GPT-5.5 có thể:
- Hiểu mục tiêu tổng thể của người dùng
- Tự chia nhỏ nhiệm vụ thành nhiều bước
- Lập kế hoạch thực hiện logic
- Tự theo dõi tiến trình và điều chỉnh khi cần
Điều này giúp AI tiến gần hơn đến vai trò “người thực thi công việc”, không chỉ là công cụ hỗ trợ thông tin.
Ví dụ, khi yêu cầu “lập kế hoạch marketing”, GPT-5.5 không chỉ đưa ý tưởng mà còn có thể xây dựng toàn bộ chiến lược, timeline và nội dung triển khai.
GPT-5.5 được cải thiện mạnh mẽ trong lĩnh vực lập trình – một trong những trọng tâm quan trọng nhất của OpenAI.
Những điểm nâng cấp đáng chú ý:
- Hiểu cấu trúc dự án lớn tốt hơn
- Giảm lỗi logic khi viết code
- Debug chính xác và có giải thích rõ ràng
- Refactor code theo hướng tối ưu hơn
Điều này đặc biệt hữu ích cho:
- Lập trình viên chuyên nghiệp
- Kỹ sư phần mềm
- Người học lập trình
GPT-5.5 không chỉ viết code mà còn có thể đóng vai trò như một “kỹ sư phần mềm ảo”.
Một cải tiến quan trọng khác của GPT-5.5 là khả năng tích hợp và sử dụng công cụ bên ngoài hiệu quả hơn.
AI có thể:
- Làm việc với file dữ liệu (Excel, CSV)
- Phân tích tài liệu dài
- Duyệt web để tìm thông tin
- Tương tác với các phần mềm khác
Điểm đáng chú ý là GPT-5.5 có thể tự quyết định dùng công cụ nào phù hợp nhất, thay vì chờ người dùng chỉ định.
Ví dụ:
- Khi xử lý bảng tính → tự thao tác dữ liệu
- Khi phân tích dữ liệu → tự dùng công cụ thống kê
- Khi cần thông tin mới → tự truy xuất web
Một trong những vấn đề cố hữu của các mô hình AI trước đây là dễ “quên” thông tin trong hội thoại dài.
GPT-5.5 đã cải thiện rõ rệt:
- Giữ ngữ cảnh ổn định hơn trong cuộc hội thoại dài
- Hiểu mối liên kết giữa nhiều yêu cầu khác nhau
- Tóm tắt và tổ chức thông tin thông minh hơn
Điều này giúp GPT-5.5 phù hợp hơn với:
- Tư vấn chiến lược doanh nghiệp
- Viết báo cáo dài
- Nghiên cứu học thuật
- Quản lý dự án nhiều bước
GPT-5.5 không chỉ dành cho lập trình mà còn được tối ưu cho môi trường công việc thực tế.
Các khả năng nổi bật:
- Viết email chuyên nghiệp
- Soạn báo cáo kinh doanh
- Phân tích dữ liệu tài chính
- Tổng hợp thông tin từ nhiều nguồn
- Hỗ trợ ra quyết định
Điều này giúp GPT-5.5 trở thành một trợ lý văn phòng AI toàn diện, đặc biệt hữu ích cho doanh nghiệp và người làm việc tri thức.
Một cải tiến quan trọng về mặt kỹ thuật là GPT-5.5:
- Xử lý nhanh hơn so với GPT-5.4
- Sử dụng ít tài nguyên hơn
- Tối ưu số lượng token trong quá trình xử lý
Điều này mang lại lợi ích lớn:
- Giảm chi phí vận hành AI
- Tăng tốc độ phản hồi
- Mở rộng khả năng ứng dụng ở quy mô lớn
Nói cách khác, GPT-5.5 vừa “thông minh hơn” vừa “hiệu quả hơn”.
OpenAI cũng đặc biệt chú trọng đến yếu tố an toàn trong GPT-5.5.
Các cải tiến chính:
- Kiểm soát nội dung nhạy cảm tốt hơn
- Giảm nguy cơ tạo nội dung độc hại
- Nhận diện yêu cầu nguy hiểm chính xác hơn
- Tăng cường cơ chế kiểm thử và đánh giá trước khi triển khai
Mục tiêu là đảm bảo GPT-5.5 có thể mạnh hơn nhưng vẫn an toàn khi sử dụng trong thực tế.
Mô hình GPT-5.5 có sẵn trong các gói ChatGPT nào?
Hiện tại, GPT-5.5 đang được triển khai cho người dùng Plus, Pro, Business và Enterprise trên ChatGPT và Codex, và GPT-5.5 Pro đang được triển khai cho người dùng Pro, Business và Enterprise trên ChatGPT. OpenAI sẽ sớm đưa GPT-5.5 và GPT-5.5 Pro lên API.
Trong ChatGPT, GPT-5.5 Thinking có sẵn cho người dùng Plus, Pro, Business và Enterprise. GPT-5.5 Pro, được thiết kế cho các câu hỏi khó hơn và yêu cầu độ chính xác cao hơn, có sẵn cho người dùng Pro, Business và Enterprise.
Trong Codex, GPT-5.5 có sẵn cho các gói Plus, Pro, Business, Enterprise, Edu và Go với cửa sổ ngữ cảnh 400K. GPT-5.5 cũng có sẵn ở chế độ Nhanh, tạo mã thông báo nhanh hơn 1,5 lần với chi phí gấp 2,5 lần.
Mặc dù GPT-5.5 có giá cao hơn GPT-5.4, nhưng nó thông minh hơn và tiết kiệm token hơn nhiều. Tại Codex, OpenAI đã tinh chỉnh trải nghiệm một cách cẩn thận để GPT-5.5 mang lại kết quả tốt hơn với ít token hơn GPT-5.4 cho hầu hết người dùng, đồng thời vẫn cung cấp thời lượng sử dụng hào phóng trên tất cả các cấp độ đăng ký.
Khả năng của mô hình
OpenAI đang xây dựng hạ tầng toàn cầu cho trí tuệ nhân tạo dạng tác nhân (agentic AI), giúp cá nhân và doanh nghiệp trên toàn thế giới có thể hoàn thành công việc bằng AI. Trong năm qua, chúng ta đã chứng kiến AI tăng tốc mạnh mẽ trong lĩnh vực kỹ thuật phần mềm. Với GPT-5.5 trong Codex và ChatGPT, sự chuyển đổi này đang bắt đầu mở rộng sang nghiên cứu khoa học và các công việc rộng hơn mà con người thực hiện trên máy tính.
Trên các lĩnh vực này, GPT-5.5 không chỉ thông minh hơn; mà còn hiệu quả hơn trong cách giải quyết vấn đề, thường tạo ra đầu ra chất lượng cao hơn với ít token hơn và ít lần thử lại hơn. Trong chỉ số lập trình của Artificial Analysis (Coding Index), GPT-5.5 mang lại mức trí tuệ hàng đầu thị trường với chi phí chỉ bằng một nửa so với các mô hình cạnh tranh thuộc nhóm tiên tiến nhất.
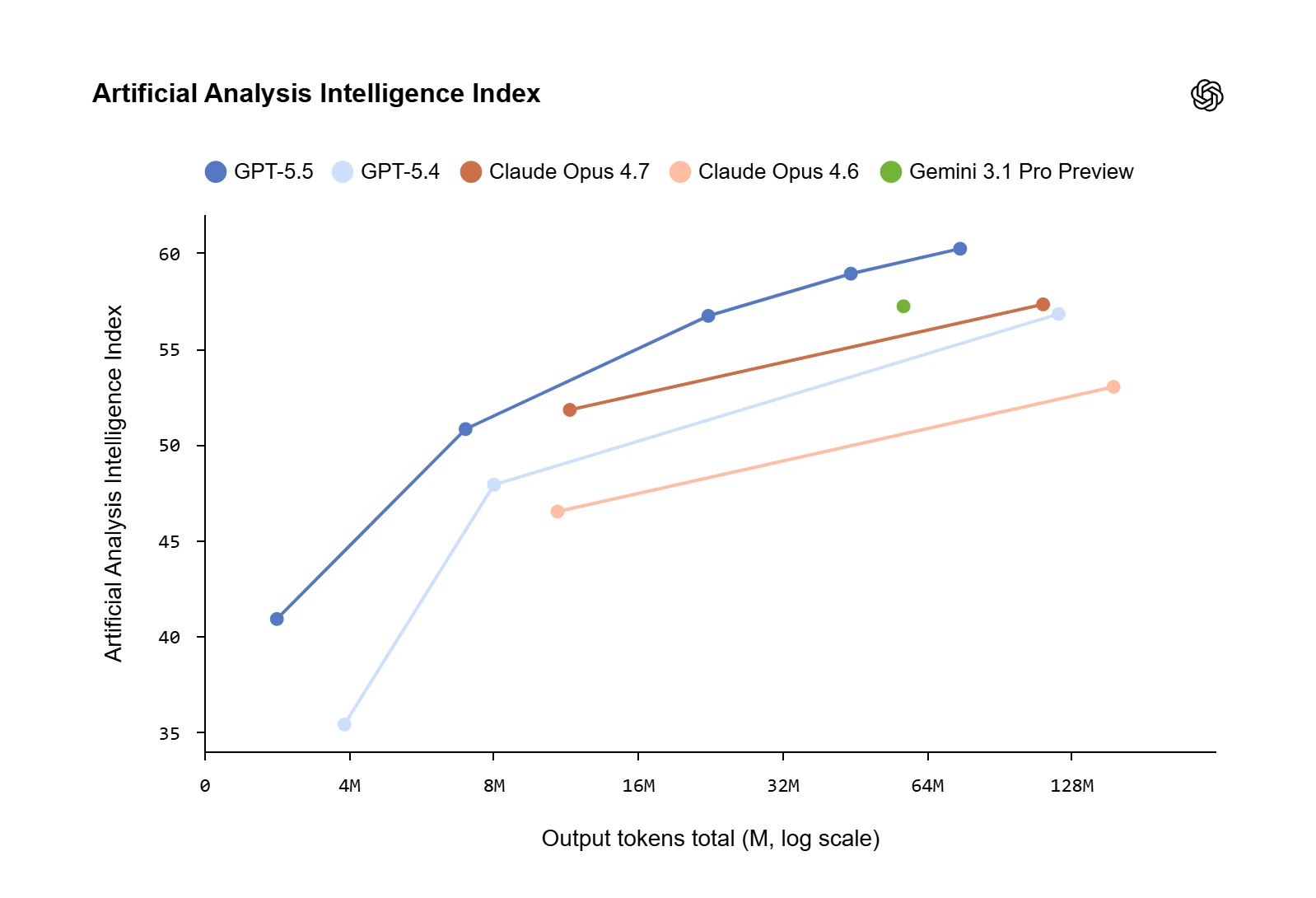
Chỉ số này (mở trong cửa sổ mới) là giá trị trung bình có trọng số của 10 bài đánh giá (benchmark) được thực hiện bởi một bên thứ ba độc lập, bao gồm: AA-LCR, AA-Omniscience, CritPt, GDPval-AA, GPQA Diamond, Humanity’s Last Exam, IFBench, SciCode, Terminal-Bench Hard, τ²-Bench Telecom.
Lập trình tác nhân (Agentic coding)
GPT-5.5 là mô hình lập trình dạng tác nhân (agentic coding) mạnh nhất của chúng tôi cho đến nay. Trên bài đánh giá Terminal-Bench 2.0, vốn kiểm tra các quy trình dòng lệnh (command-line) phức tạp đòi hỏi khả năng lập kế hoạch, lặp lại và phối hợp công cụ, mô hình đạt độ chính xác tiên tiến (state-of-the-art) là 82,7%.
Trên SWE-Bench Pro, bài đánh giá khả năng giải quyết các vấn đề thực tế trên GitHub, GPT-5.5 đạt 58,6%, giải quyết nhiều tác vụ từ đầu đến cuối chỉ trong một lần chạy hơn so với các mô hình trước đó.
Trên Expert-SWE, bài đánh giá nội bộ về các tác vụ lập trình dài hạn (long-horizon coding tasks), với thời gian hoàn thành trung bình của con người ước tính khoảng 20 giờ, GPT-5.5 cũng vượt trội hơn GPT-5.4.
Trên cả ba bài đánh giá, GPT-5.5 đều cải thiện điểm số so với GPT-5.4 trong khi sử dụng ít token hơn.
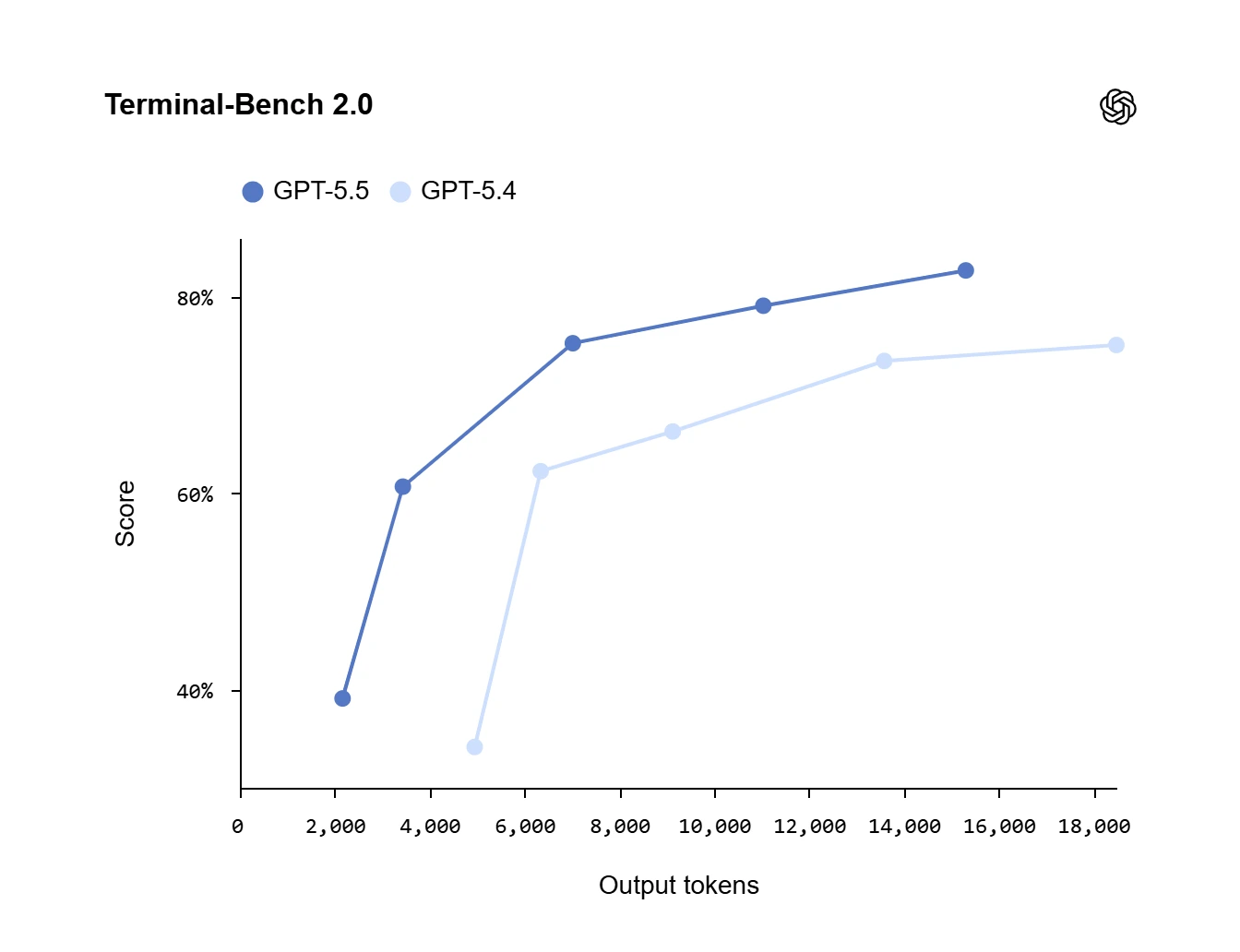
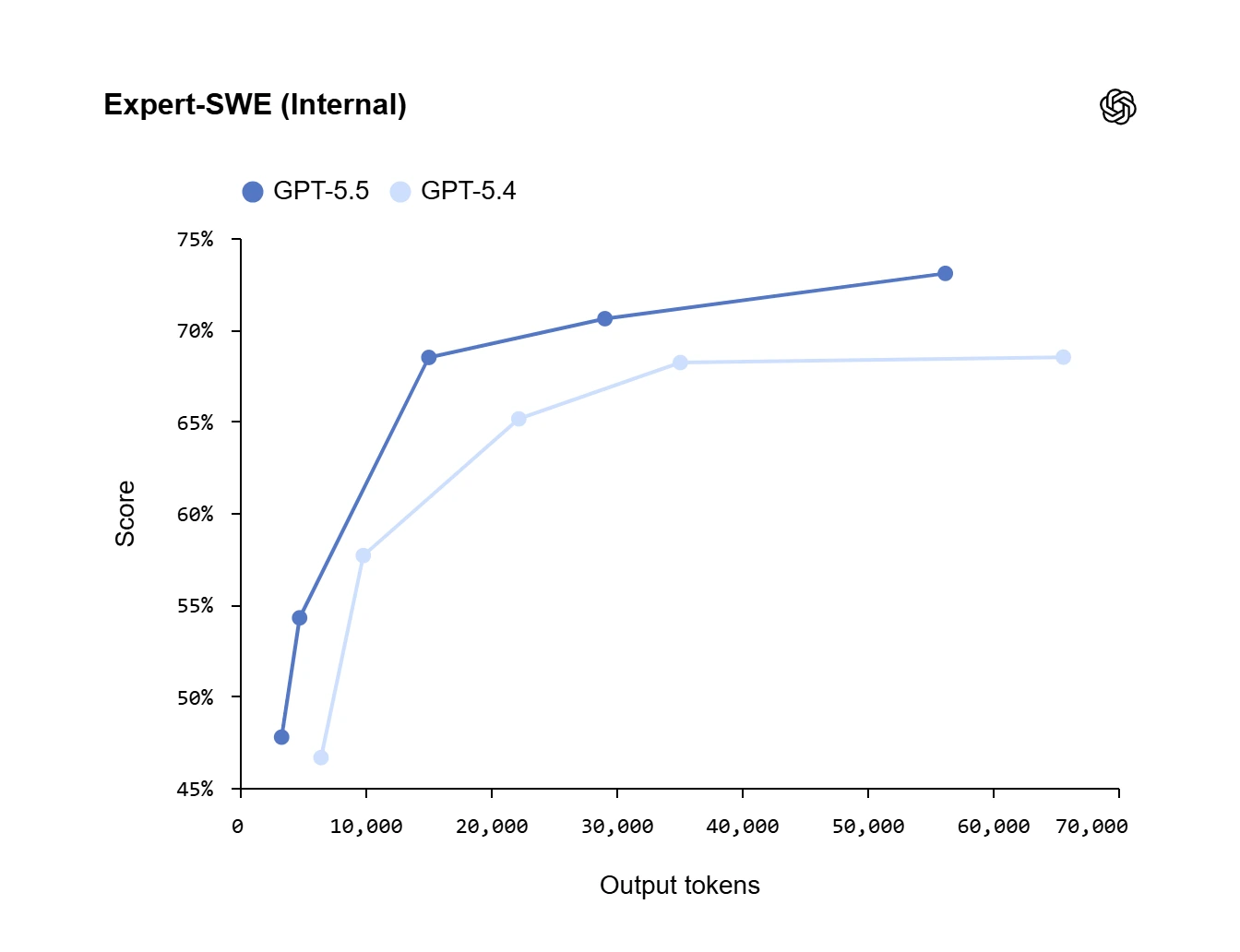
Những điểm mạnh về lập trình của mô hình thể hiện rõ rệt nhất trong Codex, nơi nó có thể đảm nhận các công việc kỹ thuật đa dạng từ triển khai tính năng, tái cấu trúc (refactor), đến gỡ lỗi (debug), kiểm thử (testing) và xác thực (validation).
Các thử nghiệm ban đầu cho thấy GPT-5.5 làm tốt hơn trong những hành vi cốt lõi mà công việc kỹ sư phần mềm thực tế phụ thuộc vào, như:
- duy trì ngữ cảnh trong các hệ thống lớn,
- suy luận qua các lỗi mơ hồ,
- kiểm tra giả định bằng công cụ,
- và triển khai thay đổi xuyên suốt toàn bộ codebase liên quan.
Ngoài các bài kiểm tra hiệu năng, những người thử nghiệm ban đầu cho biết GPT-5.5 thể hiện khả năng hiểu rõ hơn về cấu trúc của hệ thống: tại sao một thứ gì đó bị lỗi, cần khắc phục lỗi ở đâu và những phần nào khác trong mã nguồn sẽ bị ảnh hưởng.
Công việc tri thức (Knowledge work)
Những điểm mạnh giúp GPT-5.5 vượt trội trong lập trình cũng khiến nó trở nên rất mạnh trong các công việc hằng ngày trên máy tính. Vì mô hình hiểu rõ hơn về ý định của người dùng, nó có thể xử lý trọn vẹn một vòng công việc tri thức một cách tự nhiên hơn: tìm kiếm thông tin, hiểu điều gì quan trọng, sử dụng công cụ, kiểm tra kết quả và biến dữ liệu thô thành sản phẩm hữu ích.
Trong Codex, GPT-5.5 tốt hơn GPT-5.4 trong việc tạo tài liệu, bảng tính và bài thuyết trình (slide). Những người thử nghiệm sớm cho biết mô hình vượt trội so với các phiên bản trước trong các công việc như nghiên cứu vận hành, mô hình hóa bằng bảng tính và chuyển đổi dữ liệu kinh doanh phức tạp thành kế hoạch có cấu trúc.
Khi kết hợp với khả năng sử dụng máy tính của Codex, GPT-5.5 đưa chúng ta tiến gần hơn đến cảm giác rằng mô hình thực sự có thể “dùng máy tính cùng bạn”: nhìn thấy nội dung trên màn hình, nhấp chuột, nhập văn bản, điều hướng giao diện và di chuyển giữa các công cụ với độ chính xác cao.
Các nhóm tại OpenAI đã và đang sử dụng những khả năng này trong các quy trình làm việc thực tế. Hiện nay, hơn 85% nhân sự của công ty sử dụng Codex mỗi tuần trong nhiều lĩnh vực như kỹ thuật phần mềm, tài chính, truyền thông, marketing, khoa học dữ liệu và quản lý sản phẩm.
Trong bộ phận Truyền thông (Comms), nhóm đã sử dụng GPT-5.5 trong Codex để phân tích dữ liệu yêu cầu phát biểu trong 6 tháng, xây dựng hệ thống chấm điểm và đánh giá rủi ro, đồng thời xác thực một tác nhân Slack tự động, giúp các yêu cầu rủi ro thấp có thể được xử lý tự động trong khi các yêu cầu rủi ro cao vẫn được chuyển cho con người xem xét.
Trong bộ phận Tài chính, nhóm đã dùng Codex để rà soát 24.771 biểu mẫu thuế K-1 với tổng cộng 71.637 trang, áp dụng quy trình loại bỏ thông tin cá nhân, giúp rút ngắn thời gian hoàn thành công việc nhanh hơn 2 tuần so với năm trước.
Trong đội Go-to-Market, một nhân viên đã tự động hóa việc tạo báo cáo kinh doanh hàng tuần, giúp tiết kiệm khoảng 5–10 giờ làm việc mỗi tuần.
Trong ChatGPT, GPT-5.5 Thinking cung cấp hỗ trợ nhanh hơn cho các vấn đề khó khăn, với các câu trả lời thông minh và ngắn gọn hơn, giúp bạn xử lý công việc phức tạp hiệu quả hơn. Nó hoạt động xuất sắc trong các công việc chuyên nghiệp như lập trình, nghiên cứu, tổng hợp và phân tích thông tin, và các tác vụ liên quan đến tài liệu, đặc biệt khi sử dụng các plugin.
Trong GPT-5.5 Pro, những người thử nghiệm ban đầu nhận thấy sự cải thiện đáng kể cả về độ khó và chất lượng công việc mà ChatGPT có thể đảm nhận, với những cải tiến về độ trễ giúp nó trở nên thiết thực hơn nhiều đối với các tác vụ đòi hỏi cao. So với GPT-5.4 Pro, người thử nghiệm nhận thấy phản hồi của GPT-5.5 Pro toàn diện hơn, có cấu trúc tốt hơn, chính xác hơn, phù hợp hơn và hữu ích hơn đáng kể, đặc biệt là về hiệu suất trong các lĩnh vực kinh doanh, pháp lý, giáo dục và khoa học dữ liệu.
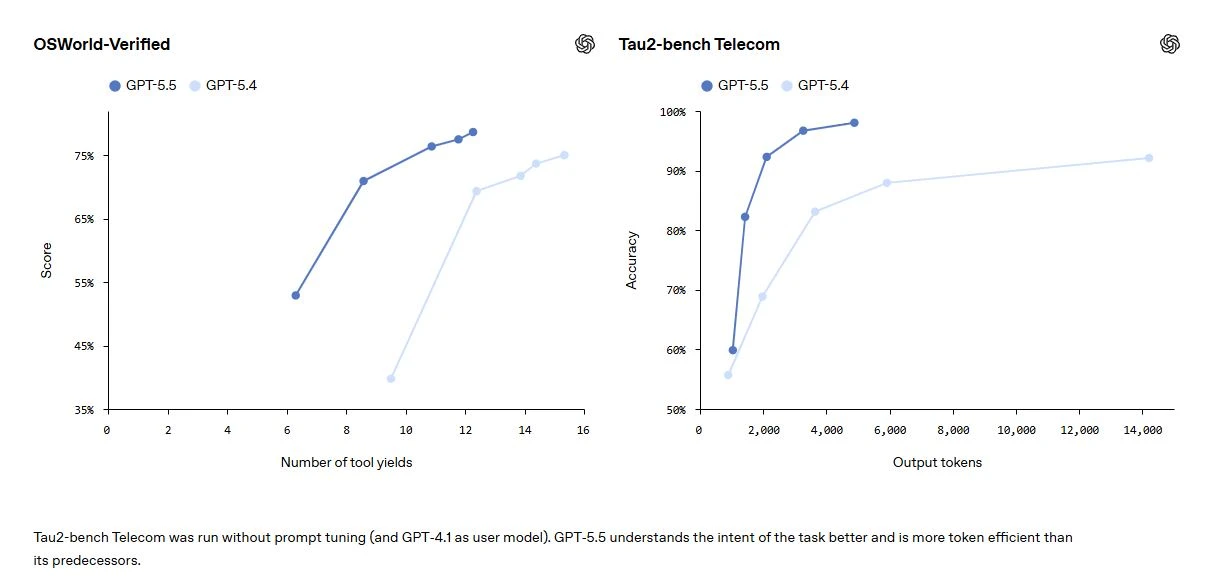
GPT-5.5 đạt hiệu suất hàng đầu trên nhiều tiêu chuẩn đánh giá phản ánh loại công việc này. Trên GDPval, bài kiểm tra khả năng của các tác nhân trong việc tạo ra các sản phẩm trí tuệ được xác định rõ ràng trên 44 ngành nghề, GPT-5.5 đạt 84,9%. Trên OSWorld
-Verified, bài kiểm tra xem một mô hình có thể tự vận hành trong môi trường máy tính thực hay không, nó đạt 78,7%.
Và trên Tau2-bench Telecom, bài kiểm tra các quy trình làm việc dịch vụ khách hàng phức tạp, nó đạt 98,0% mà không cần điều chỉnh nhanh. GPT-5.5 cũng thể hiện mạnh mẽ trên các tiêu chuẩn đánh giá công việc trí tuệ khác: 60,0% trên FinanceAgent, 88,5% trên các nhiệm vụ mô hình hóa ngân hàng đầu tư nội bộ và 54,1% trên OfficeQA Pro.
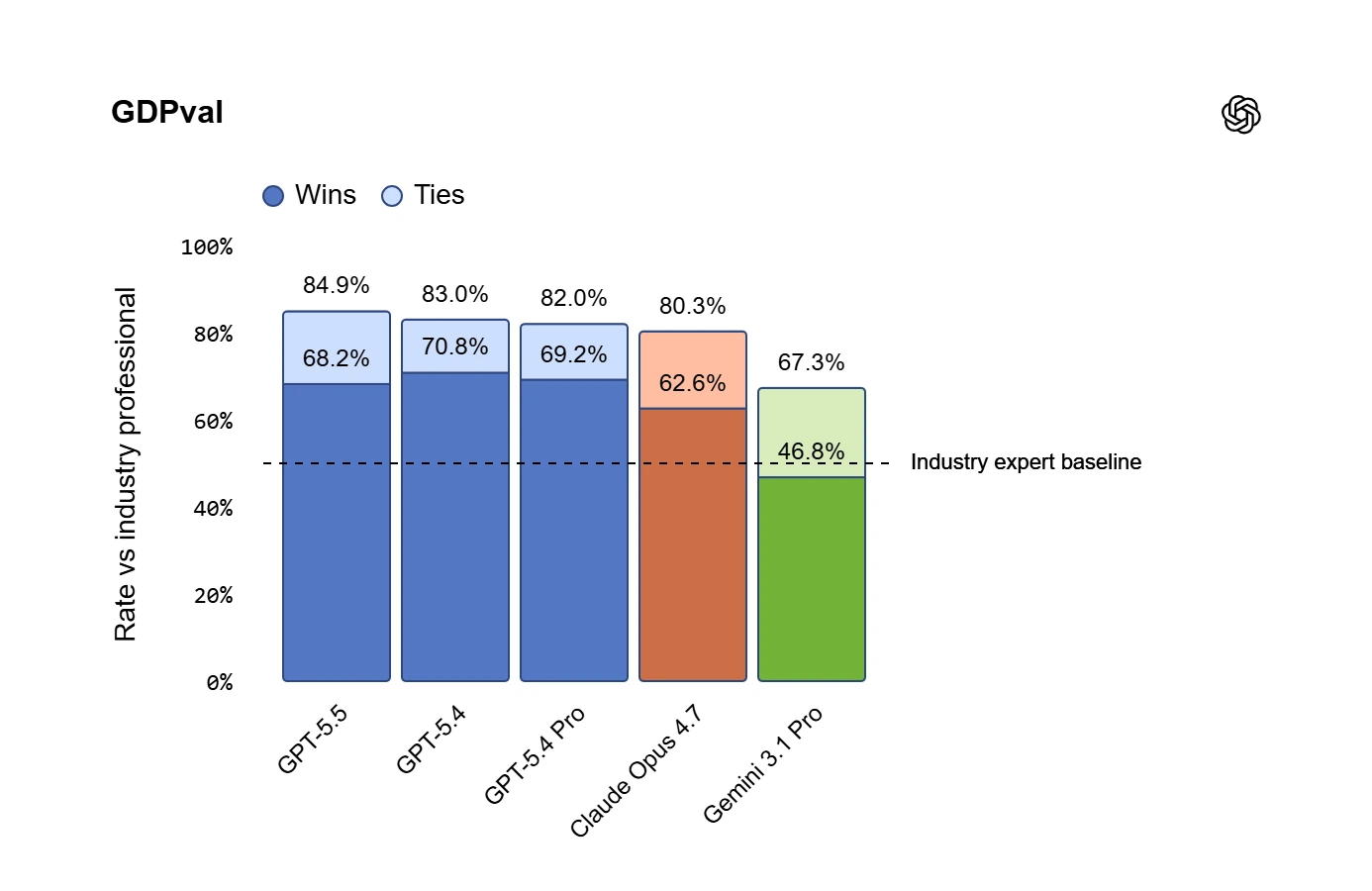
Nghiên cứu khoa học
GPT-5.5 cũng cho thấy những tiến bộ trong quy trình nghiên cứu khoa học và kỹ thuật, vốn đòi hỏi nhiều hơn là chỉ trả lời một câu hỏi khó. Các nhà nghiên cứu cần khám phá một ý tưởng, thu thập bằng chứng, kiểm tra các giả định, diễn giải kết quả và quyết định bước tiếp theo cần thực hiện. GPT-5.5 duy trì được quá trình này tốt hơn các mô hình khác.
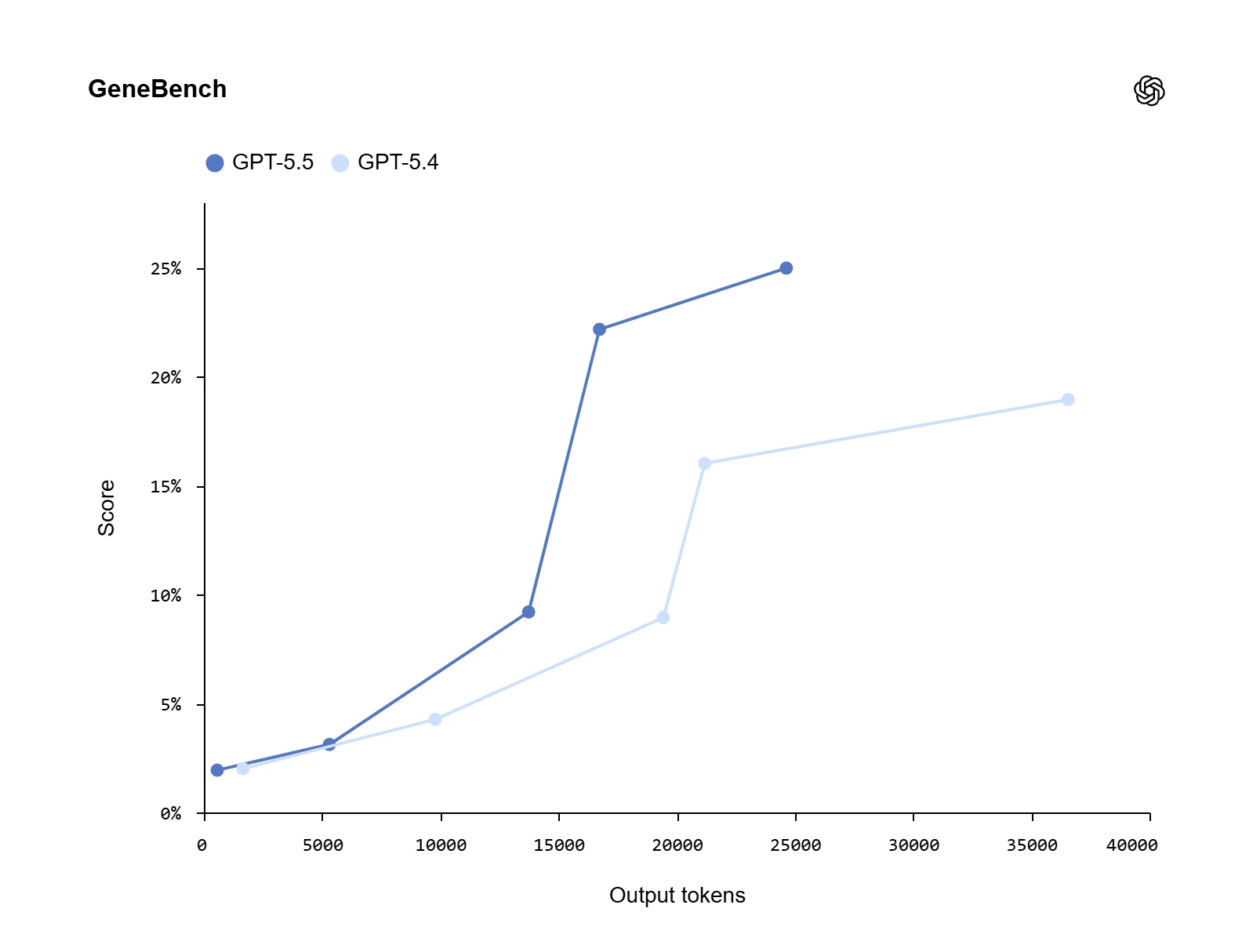
Đáng chú ý, GPT-5.5 cho thấy sự cải thiện rõ rệt so với GPT-5.4 về một đánh giá mới tập trung vào phân tích dữ liệu khoa học đa giai đoạn trong di truyền học và sinh học định lượng. Những vấn đề này đòi hỏi các mô hình phải suy luận về dữ liệu có khả năng mơ hồ hoặc sai sót với sự hướng dẫn giám sát tối thiểu, giải quyết các trở ngại thực tế như các yếu tố gây nhiễu tiềm ẩn hoặc lỗi kiểm soát chất lượng, và thực hiện cũng như diễn giải chính xác các phương pháp thống kê hiện đại.
Hiệu suất của mô hình rất ấn tượng khi xét đến thực tế là các nhiệm vụ ở đây thường tương ứng với các dự án kéo dài nhiều ngày đối với các chuyên gia khoa học.
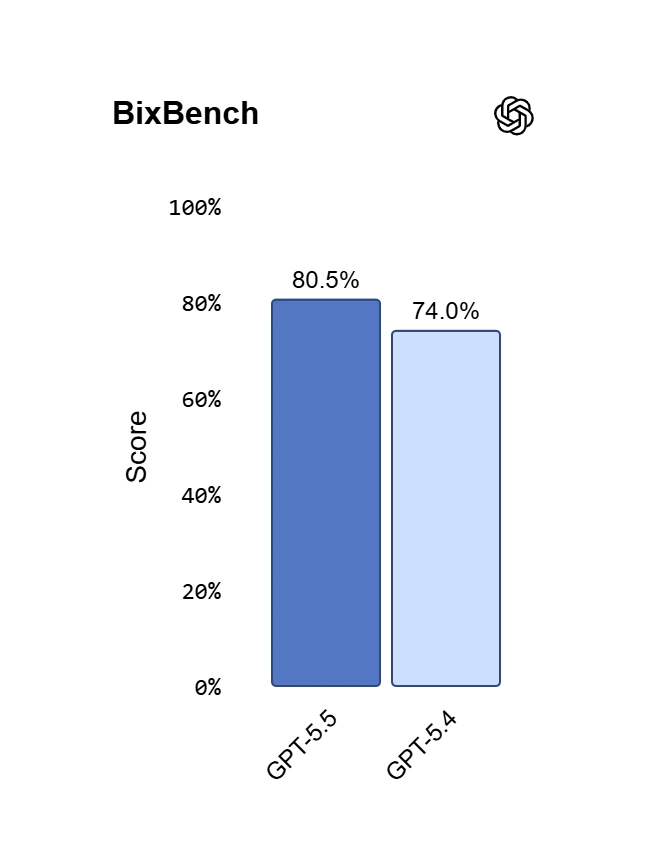
Tương tự như vậy, trên – một bài đánh giá được thiết kế xoay quanh các tác vụ tin sinh học (bioinformatics) và phân tích dữ liệu trong thế giới thực – GPT-5.5 đạt hiệu suất dẫn đầu trong số các mô hình có công bố điểm số.
Các năng lực khoa học của mô hình hiện đã đủ mạnh để có thể đẩy nhanh đáng kể tiến trình nghiên cứu ở ranh giới của khoa học y sinh, đóng vai trò như một “đồng nhà khoa học” (co-scientist) thực thụ.
Trong một ví dụ khác, một phiên bản nội bộ của GPT-5.5 với một hệ thống hỗ trợ (custom harness) đã giúp phát hiện một kết quả liên quan đến số Ramsey, một trong những đối tượng trung tâm của ngành tổ hợp (combinatorics).
Tổ hợp học nghiên cứu cách các đối tượng rời rạc liên kết với nhau: đồ thị, mạng lưới, tập hợp và các mẫu cấu trúc. Các số Ramsey đặt ra câu hỏi, một cách khái quát, rằng một mạng lưới cần lớn đến mức nào để chắc chắn xuất hiện một dạng trật tự nào đó. Các kết quả trong lĩnh vực này thường hiếm và có độ phức tạp kỹ thuật cao.
Trong trường hợp này, GPT-5.5 đã tìm ra một chứng minh cho một kết quả tiệm cận lâu đời về các số Ramsey ngoài đường chéo (off-diagonal Ramsey numbers), sau đó được xác minh lại bằng hệ thống Lean. Đây là một ví dụ cụ thể cho thấy GPT-5.5 không chỉ tạo ra mã nguồn hay giải thích, mà còn có thể đóng góp một lập luận toán học bất ngờ và hữu ích trong một lĩnh vực nghiên cứu cốt lõi.
Những người thử nghiệm sớm đã sử dụng GPT-5.5 Pro trong ChatGPT không đơn thuần như một công cụ trả lời một lần, mà giống như một đối tác nghiên cứu: cùng chỉnh sửa và phản biện bản thảo qua nhiều vòng, kiểm tra độ chắc chắn của các lập luận kỹ thuật, đề xuất phân tích, và làm việc với mã nguồn, ghi chú cũng như nội dung PDF.
Điểm chung xuyên suốt là GPT-5.5 tốt hơn trong việc giúp nhà nghiên cứu chuyển từ câu hỏi → thí nghiệm → kết quả đầu ra.
Đánh giá
| Bài đánh giá | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| SWE-Bench Pro (Công khai)* | 58.6% | 57.7% | – | – | 64.3% | 54.2% |
| Terminal-Bench 2.0 | 82.7% | 75.1% | – | – | 69.4% | 68.5% |
| Expert-SWE (Nội bộ) | 73.1% | 68.5% | – | – | – | – |
* Các phòng thí nghiệm đã ghi nhận có lưu ý (mở trong cửa sổ mới) về bài đánh giá này.
| Bài đánh giá | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| GDPval (thắng hoặc hòa) | 84.9% | 83.0% | 82.3% | 82.0% | 80.3% | 67.3% |
| FinanceAgent v1.1 | 60.0% | 56.0% | – | 61.5% | 64.4% | 59.7% |
| Tác vụ mô hình hóa ngân hàng đầu tư (nội bộ) | 88.5% | 87.3% | 88.6% | 83.6% | – | – |
| OfficeQA Pro | 54.1% | 53.2% | – | – | 43.6% | 18.1% |
| Bài đánh giá | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| OSWorld-Verified | 78.7% | 75.0% | – | – | 78.0% | – |
| MMMU Pro (không dùng công cụ) | 81.2% | 81.2% | – | – | – | 80.5% |
| MMMU Pro (có công cụ) | 83.2% | 82.1% | – | – | – | – |
| Bài đánh giá | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| BrowseComp | 84.4% | 82.7% | 90.1% | 89.3% | 79.3% | 85.9% |
| MCP Atlas** | 75.3% | 70.6% | – | – | 79.1% | 78.2% |
| Toolathlon | 55.6% | 54.6% | – | – | – | 48.8% |
| τ²-bench Telecom*** (prompt gốc) | 98.0% | 92.8% | – | – | – | – |
** MCP Atlas: kết quả từ Scale AI sau bản cập nhật tháng 4/2026
*** τ²-bench telecom: kết quả với prompt gốc, không chỉnh sửa prompt
| Bài đánh giá | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| GeneBench | 25.0% | 19.0% | 33.2% | 25.6% | – | – |
| FrontierMath Tier 1–3 | 51.7% | 47.6% | 52.4% | 50.0% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 39.6% | 38.0% | 22.9% | 16.7% |
| BixBench | 80.5% | 74.0% | – | – | – | – |
| GPQA Diamond | 93.6% | 92.8% | – | 94.4% | 94.2% | 94.3% |
| Humanity’s Last Exam (không tool) | 41.4% | 39.8% | 43.1% | 42.7% | 46.9% | 44.4% |
| Humanity’s Last Exam (có tool) | 52.2% | 52.1% | 57.2% | 58.7% | 54.7% | 51.4% |
| Bài đánh giá | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| Capture-the-Flags (nội bộ)**** | 88.1% | 83.7% | – | – | – | – |
| CyberGym | 81.8% | 79.0% | – | – | 73.1% | – |
**** Mở rộng từ các bài CTF khó nhất trong system card với các thử thách bổ sung
| Bài đánh giá | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| Graphwalks BFS 256k f1 | 73.7% | 62.5% | – | – | 76.9% | – |
| Graphwalks BFS 1M f1 | 45.4% | 9.4% | – | – | 41.2% (Opus 4.6) | – |
| Graphwalks parents 256k f1 | 90.1% | 82.8% | – | – | 93.6% | – |
| Graphwalks parents 1M f1 | 58.5% | 44.4% | – | – | 72.0% (Opus 4.6) | – |
| OpenAI MRCR v2 8-needle 4K–8K | 98.1% | 97.3% | – | – | – | – |
| 8K–16K | 93.0% | 91.4% | – | – | – | – |
| 16K–32K | 96.5% | 97.2% | – | – | – | – |
| 32K–64K | 90.0% | 90.5% | – | – | – | – |
| 64K–128K | 83.1% | 86.0% | – | – | – | – |
| 128K–256K | 87.5% | 79.3% | – | – | 59.2% | – |
| 256K–512K | 81.5% | 57.5% | – | – | – | – |
| 512K–1M | 74.0% | 36.6% | – | – | 32.2% | – |
| Bài đánh giá | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| ARC-AGI-1 (đã xác minh) | 95.0% | 93.7% | – | 94.5% | 93.5% | 98.0% |
| ARC-AGI-2 (đã xác minh) | 85.0% | 73.3% | – | 83.3% | 75.8% | 77.1% |





